
Introduction
For those coming from a relational database background, the idea of placing multiple entity types in a single DynamoDB table can initially seem counterintuitive. Keep in mind that DynamoDB is a table service, not a traditional database service. In practice, however, the one-table design pattern is not just a best practice it is recommended by AWS itself and often serves as the foundation for building scalable, cost-efficient, and high-performance applications on DynamoDB.
One-Table Pattern Explained
The one-table pattern is a data modeling technique that stores all of an application's entities such as users, orders, products, and comments in a single DynamoDB table. Unlike relational databases, which create separate tables for each type of entity, this method relies on a flexible schema using partition keys (PK), sort keys (SK), and smart use of Global Secondary Indexes (GSIs) to make everything work efficiently.
The one-table design offers significant advantages for building efficient and manageable applications. Storing multiple entity types in a single DynamoDB table improves performance, lowers costs, and simplifies operations, creating a system that is both scalable and resilient.
Performance Benefits:
- Reduced latency by fetching related data in single queries
- Ability to retrieve multiple entity types in one request
- Efficient use of DynamoDB's querying capabilities
Cost Efficiency:
- Fewer tables mean lower baseline costs
- Better utilization of provisioned capacity
- Reduced overhead for on-demand billing
Operational Simplicity:
- Fewer tables to manage and monitor
- Simplified backup and restore procedures
- Easier capacity planning
Core Concepts
Before exploring the implementation, it's important to understand a few key concepts that will provide the foundation for the next sections.
Primary Key Design
In DynamoDB, every table requires a primary key that uniquely identifies each item. When using a composite primary key, it consists of two parts:
- Partition Key (PK): Determines how data is distributed across storage partitions. Items with the same partition key are stored together, which makes related data easier to query efficiently.
- Sort Key (SK): Defines the order of items within a partition and allows for sorting and range-based queries. This makes it possible to fetch related records quickly without scanning the entire table.
Generic Attribute Names
When storing multiple types of items in a single table (such as users, orders, and products), it is better to avoid specific key names like userId or orderId.
Generic names such as PK (Partition Key) and SK (Sort Key) should be used instead. For secondary indexes, common names like GSI1PK and GSI1SK are typically used.
This naming approach allows various entity types to coexist within the same table, as the key values themselves define what each item represents.
Example:
- User item → PK = USER#123, SK = METADATA
- Order item → PK = USER#123, SK = ORDER#456
Hierarchical Data
Related entities can be grouped under the same Partition Key (PK). This makes it possible to fetch an entire relationship like a parent and all its children in a single query.
For example, consider a system that stores users and their orders. All items related to the same user share the same PK, but have different Sort Keys (SK).
- User profile → PK = USER#123, SK = METADATA
- Order 1 → PK = USER#123, SK = ORDER#1
- Order 2 → PK = USER#123, SK = ORDER#2
- Order 3 → PK = USER#123, SK = ORDER#3
With this structure, a single query on PK = USER#123retrieves the user profile and all orders at once.
Implementation
In this section, we will implement the one-table pattern through the example of Users, Products and Orders using Nodejs with the AWS SDK to interact with DynamoDB but the same logic can be applied using any other supported programming language.
Setting Up the Project
First, let's start by defining two global variables that we will use later client and docClient and the table name in our case AppTable as it is a generic name

AppTable
import { DynamoDBClient } from '@aws-sdk/client-dynamodb';
import {
DynamoDBDocumentClient,
PutCommand,
QueryCommand,
GetCommand,
} from '@aws-sdk/lib-dynamodb';
const client = new DynamoDBClient({ region: 'eu-central-1' });
const docClient = DynamoDBDocumentClient.from(client);
const TABLE_NAME = 'AppTable';The client is the low-level DynamoDB client that communicates directly with DynamoDB using raw data formats.
The docClient is a higher-level wrapper around client that allows working with plain JavaScript objects for easier DynamoDB operations.
Designing the Key Structure
Here's how we'll structure our keys:
## Users
PK: USER#<userId>
SK: METADATA
## Orders
PK: USER#<userId>
SK: ORDER#<orderId>
## Products
PK: PRODUCT#<productId>
SK: METADATA
## Order Items
PK: ORDER#<orderId>
SK: PRODUCT#<productId>
Creating Entities
Now we are ready to start defining functions that will be used to create entities in the table, beginning with the main entity user.
async function createUser(userId, userData) {
const params = {
TableName: TABLE_NAME,
Item: {
PK: `USER#${userId}`,
SK: 'METADATA',
EntityType: 'User',
userId,
email: userData.email,
name: userData.name,
createdAt: new Date().toISOString(),
// GSI for email lookup
GSI1PK: `EMAIL#${userData.email}`,
GSI1SK: `USER#${userId}`,
},
};
await docClient.send(new PutCommand(params));
return params.Item;
}The createUser function creates a new user item in the DynamoDB table. It takes a userId and userData (like email and name) and constructs an item with a partition key (PK), sort key (SK), and other attributes. It also sets up a global secondary index (GSI) for looking up users by email. Finally, it uses docClient.send(new PutCommand(params)) to insert the item into the table and returns the created item. We could add more fields like password or role, but for the sake of this post, we are using only simple attributes.
// Product Management
async function createProduct(productId, productData) {
const params = {
TableName: TABLE_NAME,
Item: {
PK: `PRODUCT#${productId}`,
SK: 'METADATA',
EntityType: 'Product',
productId,
name: productData.name,
price: productData.price,
category: productData.category,
// GSI for category queries
GSI1PK: `CATEGORY#${productData.category}`,
GSI1SK: `PRODUCT#${productId}`,
},
};
await docClient.send(new PutCommand(params));
return params.Item;
}The createProduct function adds a new product item to the DynamoDB table. It uses productId as the primary key and stores details like name, price, and category. A GSI is also defined with GSI1PK and GSI1SK to allow efficient querying of products by category. The function inserts the item into the table and returns the created product.
async function createOrder(userId, orderId, orderData) {
const params = {
TableName: TABLE_NAME,
Item: {
PK: `USER#${userId}`,
SK: `ORDER#${orderId}`,
EntityType: 'Order',
orderId,
userId,
status: orderData.status,
total: orderData.total,
createdAt: new Date().toISOString(),
// GSI for querying orders by status
GSI1PK: `ORDERSTATUS#${orderData.status}`,
GSI1SK: orderId,
},
};
await docClient.send(new PutCommand(params));
return params.Item;
}The createOrder function creates a new order item in the DynamoDB table. It uses userId and orderId to build the primary key and stores details like status, total, and creation date. It also sets up a GSI with GSI1PK and GSI1SK to allow efficient querying of orders by their status. The function inserts the item into the table and returns the created order.
To see the beauty of this pattern, let's orchestrate all these functions in one place and run them.
async function main() {
await createUser(1, { email: 'test@gmail.com', name: 'test' });
await createProduct(101, {
name: 'Laptop',
price: 1200,
category: 'Electronics',
});
await createOrder(1, 101, { status: 'PENDING', total: 250 });
}
main();
Result from the UI console
Querying Patterns
The real advantage of this pattern is the power and flexibility it provides for querying. The code snippets below illustrate several use cases based on our example.
// Get user and all their orders in ONE query
async function getUserWithOrders(userId) {
const params = {
TableName: TABLE_NAME,
KeyConditionExpression: 'PK = :pk',
ExpressionAttributeValues: {
':pk': `USER#${userId}`,
},
};
const result = await docClient.send(new QueryCommand(params));
const user = result.Items.find((item) => item.SK === 'METADATA');
const orders = result.Items.filter((item) => item.SK.startsWith('ORDER#'));
return { user, orders };
}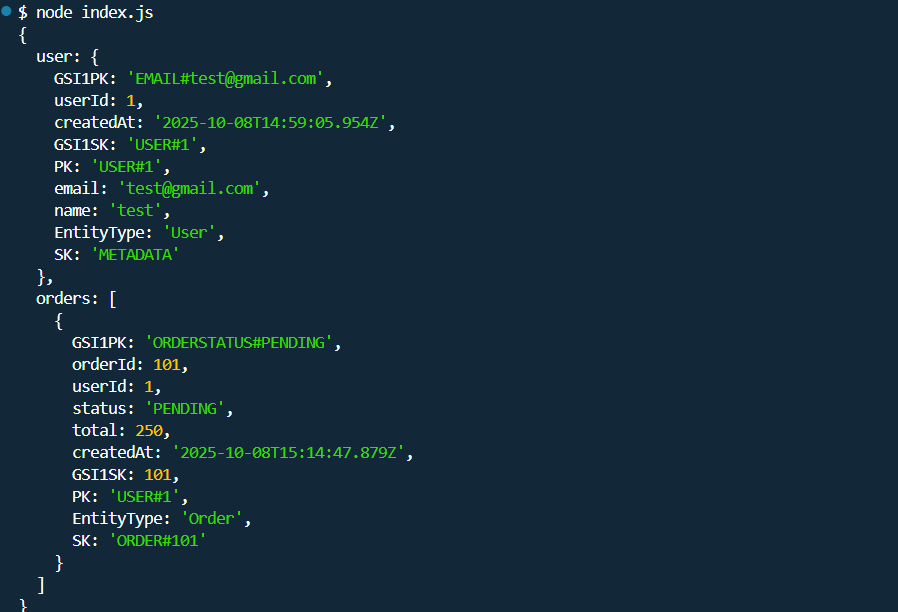
Response of the getUserWithOrders
// Find user by email using GSI
async function getUserByEmail(email) {
const params = {
TableName: TABLE_NAME,
IndexName: 'GSI1',
KeyConditionExpression: 'GSI1PK = :gsi1pk',
ExpressionAttributeValues: {
':gsi1pk': `EMAIL#${email}`,
},
};
const result = await docClient.send(new QueryCommand(params));
return result.Items[0];
}
// Get all orders with a specific status
async function getOrdersByStatus(status) {
const params = {
TableName: TABLE_NAME,
IndexName: 'GSI1',
KeyConditionExpression: 'GSI1PK = :gsi1pk',
ExpressionAttributeValues: {
':gsi1pk': `ORDERSTATUS#${status}`,
},
};
const result = await docClient.send(new QueryCommand(params));
return result.Items;
}These functions show how to query items using GSIs in the DynamoDB table.
getUserByEmail(email): Queries the GSI1 index to find a user by their email and returns the first matching item.
getOrdersByStatus(status): Queries the same index to retrieve all orders with a specific status and returns the matching items.
Both functions use the GSI partition key to efficiently fetch items without scanning the whole table.
// Get products by category
async function getProductsByCategory(category) {
const params = {
TableName: TABLE_NAME,
IndexName: 'GSI1',
KeyConditionExpression: 'GSI1PK = :gsi1pk',
ExpressionAttributeValues: {
':gsi1pk': `CATEGORY#${category}`,
},
};
const result = await docClient.send(new QueryCommand(params));
return result.Items;
}The getProductsByCategory(category) function queries the GSI1 index to retrieve all products within a specific category. It uses the GSI partition key to efficiently fetch items without scanning the entire table and returns the matching products.
Performance Optimization
This section will cover some performance optimizations that will help improve DynamoDB queries in terms of speed and cost.
Batch Operations
Use batch operations for efficiency:import { BatchWriteCommand } from '@aws-sdk/lib-dynamodb';
async function batchCreateProducts(products) {
const chunks = chunkArray(products, 25); // DynamoDB batch limit
for (const chunk of chunks) {
const params = {
RequestItems: {
[TABLE_NAME]: chunk.map((product) => ({
PutRequest: {
Item: {
PK: `PRODUCT#${product.id}`,
SK: 'METADATA',
...product,
},
},
})),
},
};
await docClient.send(new BatchWriteCommand(params));
}
}Projection Expressions
Only retrieve the needed attributes:async function getUserEmail(userId) {
const params = {
TableName: TABLE_NAME,
Key: { PK: `USER#${userId}`, SK: 'METADATA' },
ProjectionExpression: 'email, #n',
ExpressionAttributeNames: { '#n': 'name' },
};
const result = await docClient.send(new GetCommand(params));
return result.Item;
}Consistent Reads
Use consistent reads only when necessary, as they cost twice as much:const params = {
TableName: TABLE_NAME,
Key: { PK: `USER#${userId}`, SK: 'METADATA' },
ConsistentRead: true, // Be careful with this
};Conclusion
The DynamoDB one-table pattern is a paradigm shift from traditional database design, but it unlocks the full power of DynamoDB's performance and scalability. By carefully planning your access patterns, using generic key names, and leveraging GSIs strategically, we can build highly efficient applications that scale seamlessly.